案例
真实场景,带测量边界的交付结果
以下案例基于真实业务流程整理,部分信息已匿名化,重点展示交付结构、结果指标和测量方法。
01
内容运营某财经内容团队(匿名)
日更内容生产 Agent
交付前
人工找热点、整理素材、改写多平台文案,日均 3-4 小时,风格稳定性差。
Agent Workflow
热点监控 -> 选题评分 -> 风格匹配 -> 多格式草稿输出 -> 人工审核
背景与问题
团队每天都要在固定渠道保持更新,但首轮选题和改写高度依赖熟练编辑,节奏不稳。
方案设计
把选题输入、风格规则、渠道格式和审核边界写成可重复执行的工作流,压缩首轮草稿准备时间。
40min
首轮草稿准备时间
3x
周发布频率提升
95%
内部风格一致性评分
测量方法
- Measurement period:14 天内容生产评审期。
- Baseline:团队原流程中,人工搜集热点、整理素材和多平台改写通常需要 3-4 小时/天。
- After:把趋势监控、选题评分和风格匹配做成固定流程后,首轮草稿准备压缩到约 40 分钟。
- Interpretation boundary:95% 的“风格一致性评分”来自该匿名案例内部审稿检查表,不是行业公开基准。
交付内容
平台化 Prompt 规则选题评分流程多渠道输出结构测试用例与审核说明
适合:需要稳定做多平台内容分发的小团队不适合:依赖深度原创调查或实时事实采访的内容组织
02
客服运营某跨境电商团队(匿名)
客服 FAQ 回复与工单分流 Agent
交付前
每天 200+ 条消息,人工逐条判断与回复,平均首响 45 分钟。
Agent Workflow
接收消息 -> FAQ 匹配 -> 高置信度回复草稿 -> 低置信度分流 -> 人工升级
背景与问题
大部分问题重复,但风险边界又不能模糊,导致客服团队只能保守地全部人工首轮处理。
方案设计
把 FAQ 覆盖范围、禁止动作、升级规则和人工接管条件写清楚,让低风险问题先进入自动化首轮处理。
78%
FAQ 覆盖请求自动首处率
<2min
FAQ 首轮响应时间
0
验证样本订单误操作
测量方法
- Measurement period:14 天客服消息评审窗口。
- Input sample:日均 200+ 条客户消息中的 FAQ 覆盖请求样本。
- Baseline:人工首响约 45 分钟,且约 70% 问题属于重复 FAQ 场景。
- After:FAQ 匹配、低风险自动回复和低置信度升级,把 FAQ 覆盖请求的首轮处理压缩到 2 分钟内。
- Interpretation boundary:78% 指 FAQ 覆盖请求在首轮由系统完成回复或草稿;0 incidents 指验证样本内未出现订单误操作。
交付内容
FAQ 工作流说明回复模板与升级规则分类路由文档测试样本与风险边界
适合:每天有稳定高频 FAQ 的电商和 SaaS 团队不适合:需要实时语音沟通或强判断型争议处理的场景
03
内部运营某 SaaS 运营部门(匿名)
内部周报汇总 Agent
交付前
周报靠人工收集、整理、汇总,格式不统一,管理层很难快速扫描异常。
Agent Workflow
结构化输入 -> 字段整理 -> 异常标记 -> 标准化摘要草稿 -> 人工复核
背景与问题
团队每周都在重复做 copy/paste 汇总,但关键风险常常淹没在杂乱文本里。
方案设计
统一输入模板和摘要结构,让报告先变成可比较的草稿,再由 owner 做最后解释。
8min
部门级汇总时间
100%
模板字段标准化率
3
周均识别风险项
测量方法
- Measurement period:连续 4 周内部汇总对比。
- Baseline:HR 每周约花 2 小时整理周报,格式不统一、横向比较困难。
- After:结构化输入和标准化摘要草稿将部门级汇总压缩到约 8 分钟。
- Interpretation boundary:100% 标准化率指模板字段一致;周均 3 个风险项表示流程能稳定暴露异常,并非固定承诺。
交付内容
输入模板摘要工作流异常标记规则分发与复核说明
适合:有固定周报、月报或项目汇总模板的团队不适合:每个人工作内容差异极大且没有统一汇总结构的团队
交付样例
以下截图来自匿名化交付样例。
Agent Spec

Workflow
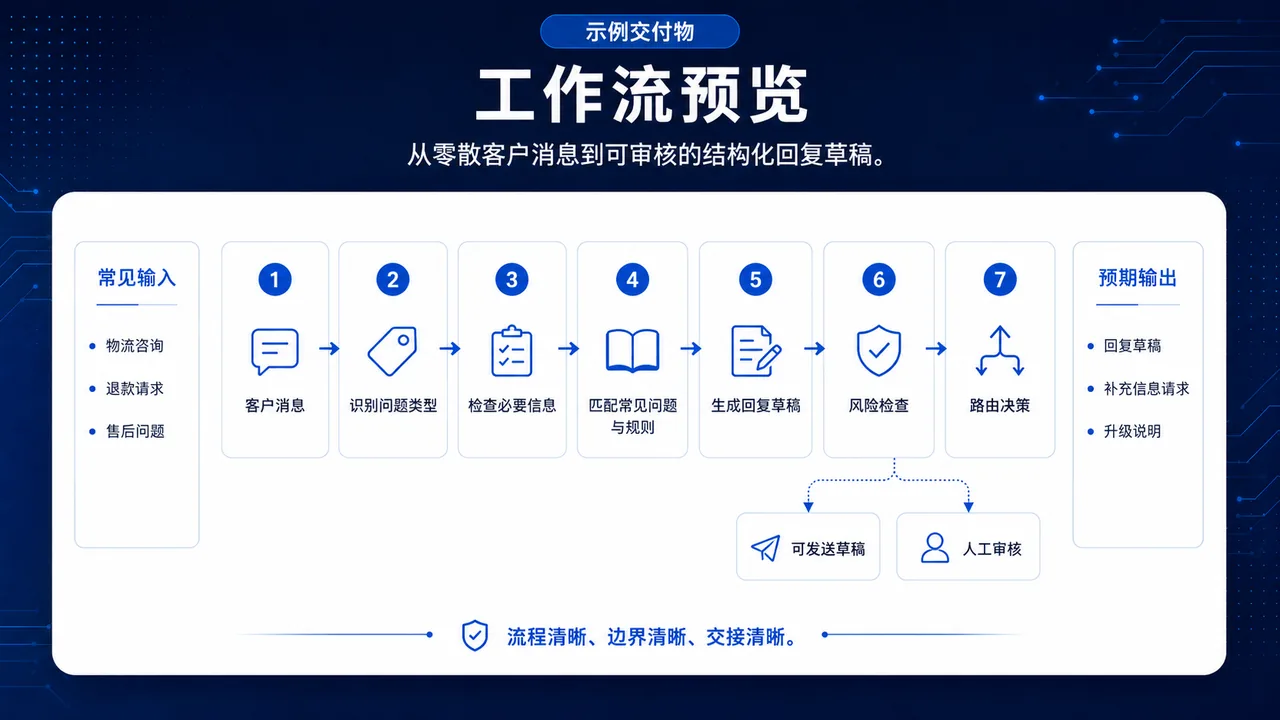
Test Cases

Deployment Guide
