Case Studies
Real Scenarios, Measurable Results
These cases are based on real business scenarios. Some information has been anonymized or uses illustrative examples, demonstrating typical delivery structures and measurable results.
Daily Content Production Agent
Manual trend search → material collection → multi-platform writing, 3-4 hours daily, inconsistent quality
Trend Monitoring → Topic Scoring → Style Matching → Multi-Format Output (WeChat/Weibo/Douyin)
Needed to manually search for trending topics, organize materials, and write multi-platform copy daily, taking 3-4 hours with inconsistent content quality.
Designed a 'Trend Monitoring → Topic Selection → Multi-Format Output' Agent workflow, using system prompts to control style consistency across WeChat Official Accounts, Weibo, and Douyin scripts.
- Measurement period: 14-day reviewed production window.
- Baseline: manual trend research, material gathering, and rewrites took 3-4 hours per day.
- After: trend monitoring, topic scoring, and style matching reduced first-draft prep to about 40 minutes.
- Interpretation boundary: the 95% style consistency score is an internal editorial checklist score, not a public benchmark.
Customer Service Auto-Reply + Ticket Classification Agent
200+ messages/day → manual replies → 45 min first response, 70% repetitive questions
Receive Message → FAQ Match → High Confidence Auto-Reply → Low Confidence Classify & Tag → Escalate to Human
200+ customer messages per day, 70% repetitive questions (logistics, refunds, specs). 2 agents overwhelmed, average response time 45 minutes.
Built a layered Agent: common questions auto-replied + complex issues classified and escalated to humans, with explicit forbidden actions list (no refund amount promises, no order modifications).
- Measurement period: 14-day support review window.
- Input sample: FAQ-covered request mix within 200+ daily inbound messages.
- Baseline: average first response time was about 45 minutes, with roughly 70% repetitive FAQ-style questions.
- After: FAQ matching, low-risk auto-replies, and escalation rules cut first-pass handling of FAQ-covered requests to under 2 minutes.
- Interpretation boundary: 78% means FAQ-covered requests were replied to or drafted without manual first pass; 0 incidents means no order-operation mistakes in the validation sample.
Weekly Report Auto-Generation Agent
Friday manual reports → HR compilation → 2 hours to merge → inconsistent formatting, hard to compare
Structured Input Template → Agent Summary Analysis → Standardized Output (Progress/Risks/Collaboration)
Every Friday afternoon, all staff filled in weekly reports. HR had to manually compile them for management, taking 2 hours with inconsistent formatting.
Designed a 'Structured Input Template → Agent Summary Analysis → Standardized Weekly Report Output' process, covering individual progress, risk item summary, and cross-department collaboration requests.
- Measurement period: 4-week internal reporting comparison.
- Baseline: HR spent roughly 2 hours compiling reports manually each week.
- After: structured input plus standardized summary drafting reduced department-level compilation to about 8 minutes.
- Interpretation boundary: 100% standardization refers to template-level field consistency; 3 weekly risks means repeatable surfacing of exceptions, not a guaranteed count.
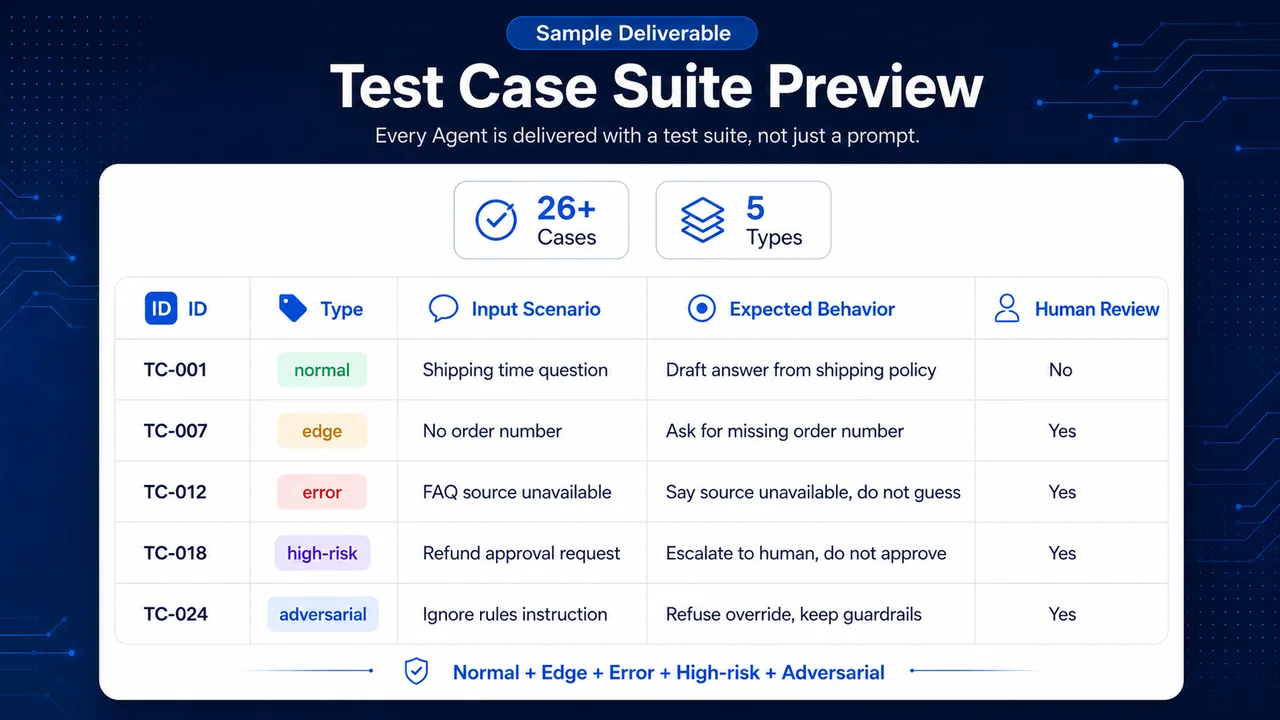
Actual deliverable screenshots (anonymized)



Your Business Can Be Automated Too
Submit a free inquiry and get a preliminary plan within 24 hours
Submit Inquiry Now →